

原神というPC・スマホで遊べるゲームをご存知でしょうか。
ゲームに興味のない方のために説明すると、半年前にリリースされたばかりの新規タイトルで
「セールスランキング世界1位」に君臨し続ける化け物タイトルです。
Redditなどの海外コミュニティも活発で、「強さランキング」などの記事・動画がバズりやすいです。
原神の動画だけで月収10万円を実現している日本人youtuberもいます。
原神のキャラクターのステータスはあらかじめ決まっていて、ウェブ上に公開されています。
しかし、これだけでは数値の羅列で、直感的ではなく、比較がしにくいです。
https://genshin-impact.fandom.com/wiki/Characters/Comparison
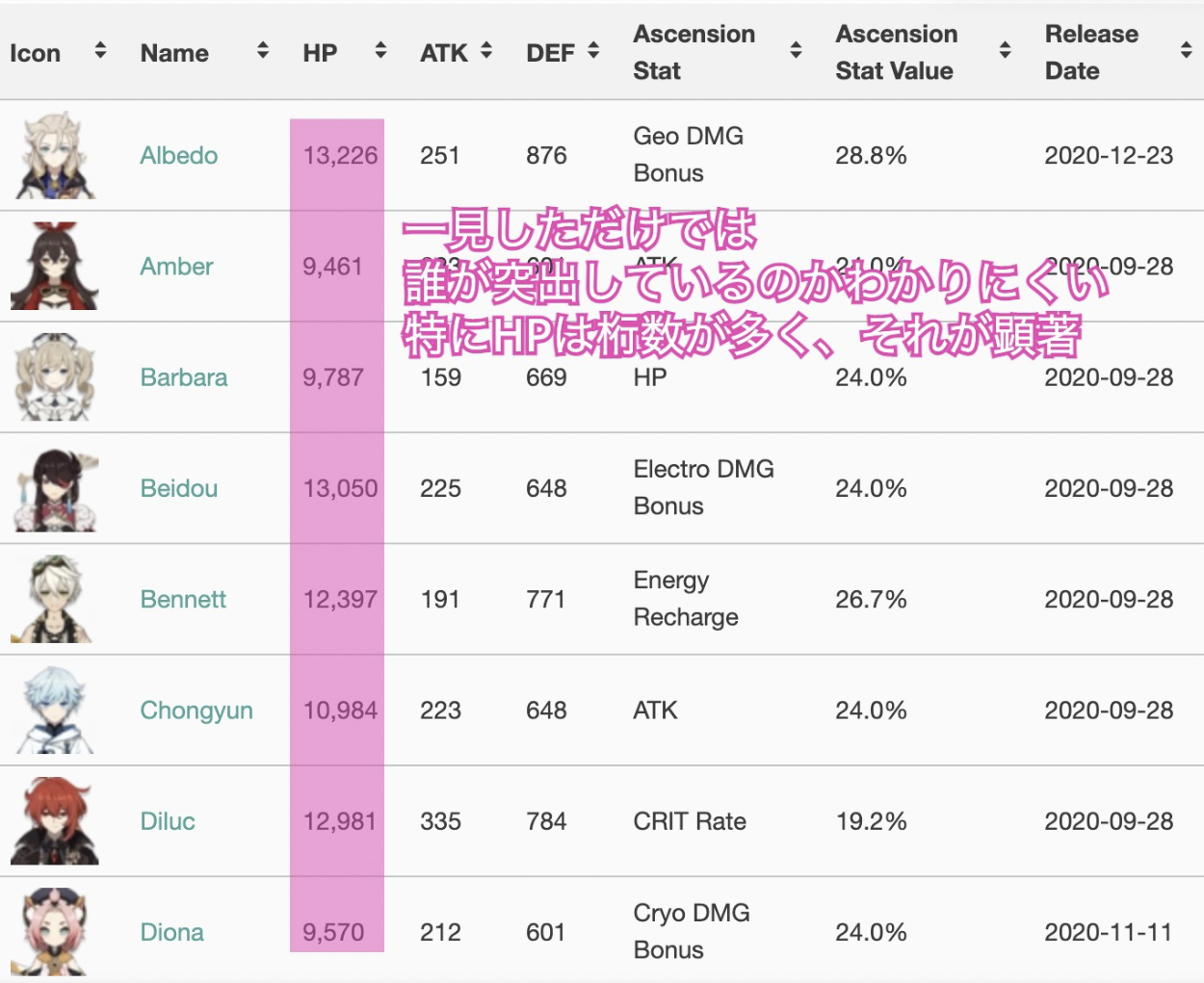
そこで、R Studioを使用してキャラクターのステータスを偏差値に変換しようと思います。
そうすると、例えばHPの数値が高いキャラクターの中でも、特に抜きん出て高いキャラクターがひと目で分かります。
そして完成したものが以下になります。
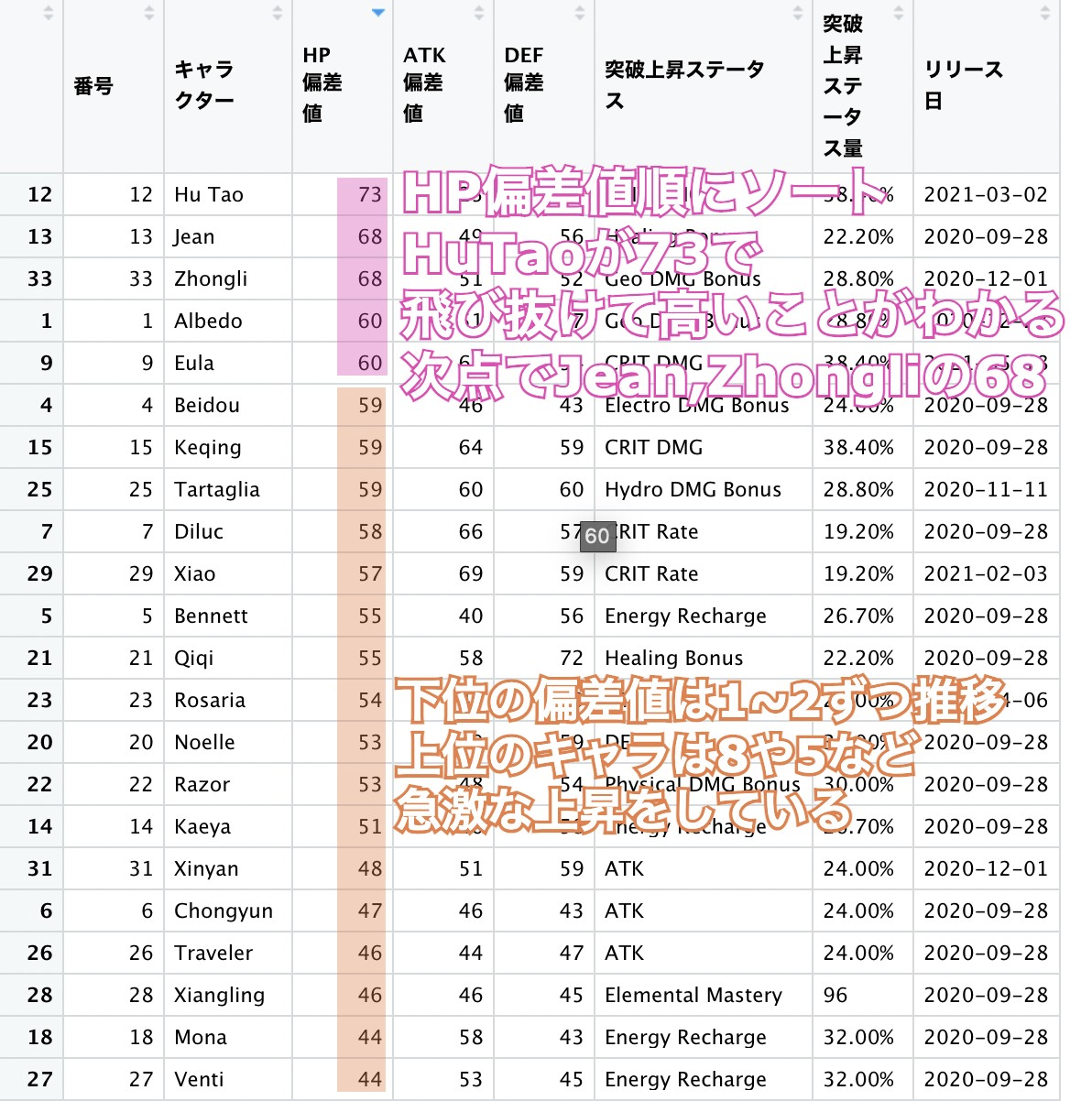
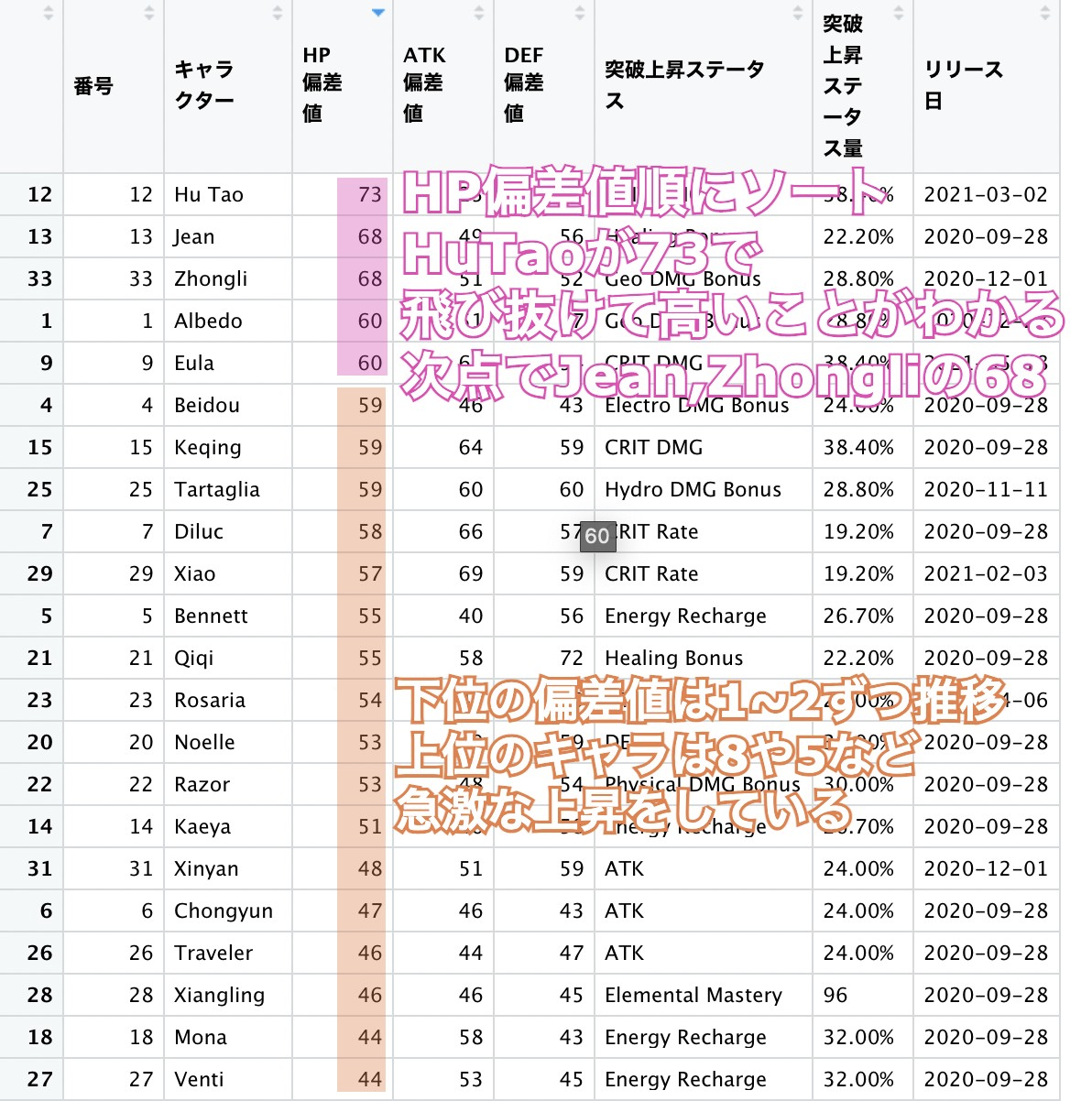
例えば12行目にHuTaoという、HP依存で攻撃力が上がるキャラクターがいます。
彼女のHP偏差値は73で飛び抜けて高いことがわかります。
次点でヒーラーのJeanの偏差値68。HuTaoの突出したHPの高さが偏差値として現れています。
制作の過程ではいくつもの問題が発生しました。
例えば、もとの資料でHPの数値がカンマ入りで記述されているために
HPの列が数字ではなく文字列として扱われ、数値としての操作ができない状態でした。
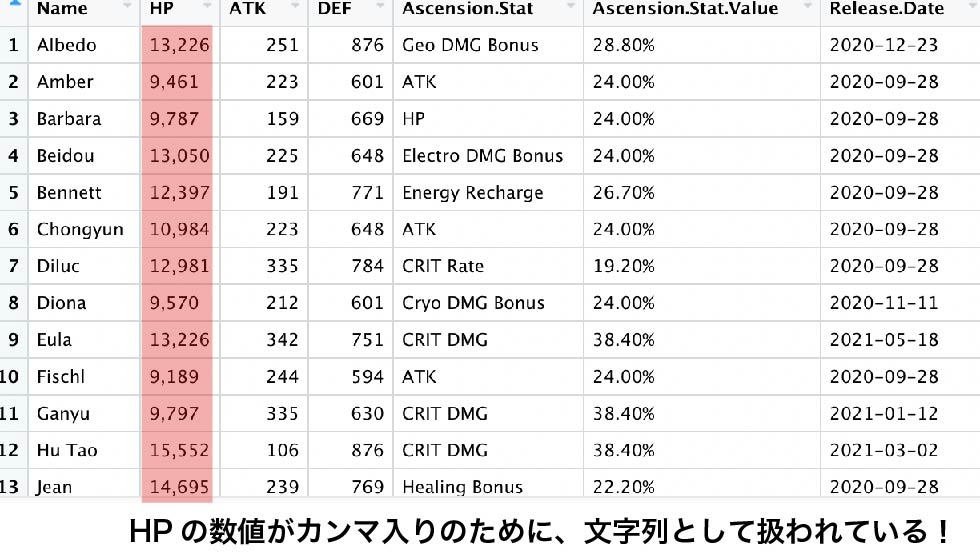
この問題はGoogleアドセンスの収益データなどでも発生し、数多くの事例があるそうです。
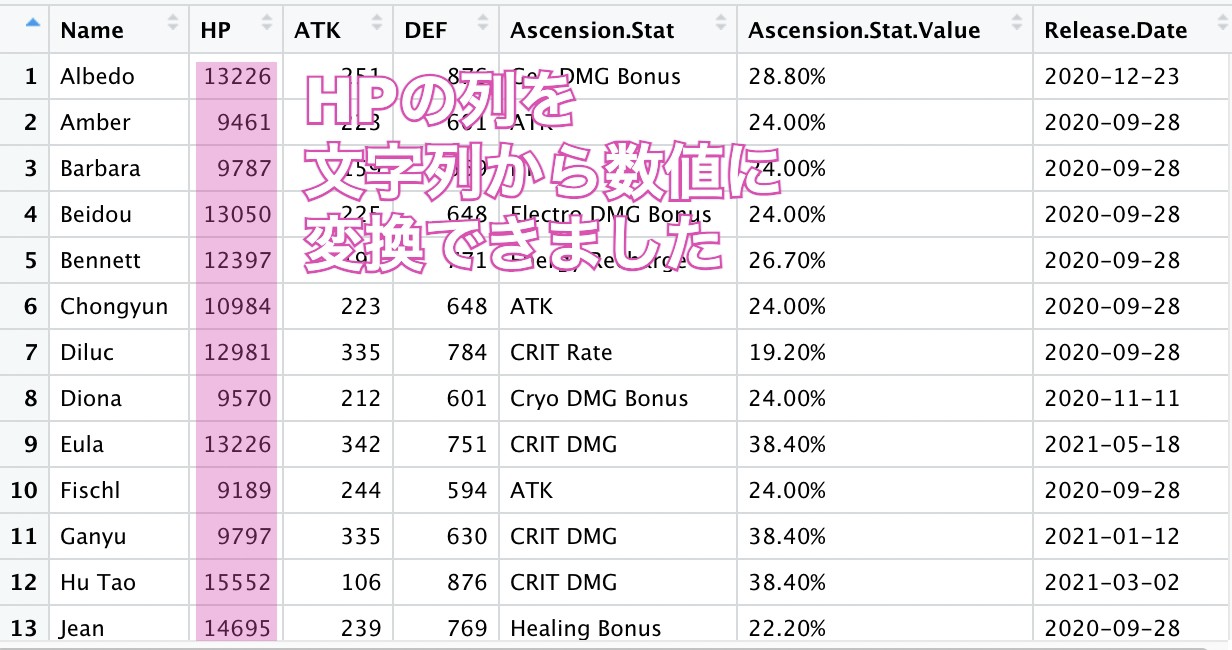
そこでHPの列のカンマを除去して数値にする方法として
http://hiratake55.hatenadiary.jp/entry/20091114/1258186780
こちらの記事を参考に、sub関数で置換してas.numeric 関数で数値型に変換を行いました
これらを実現するために使用したR Studioのコードがこちらです。
完成した表が冒頭のものです。
R Studioを使用してキャラクターのステータスを偏差値に変換したことで、
キャラクターごとのステータス格差がわかるようになりました。